

TLDR
Mini-map navigation: Global view of all infrastructure in one glance. Most strategy games have this, enterprise software doesn’t. Reduces cognitive load so you can focus on solving problems instead of hunting for resources.
Information where you need it: Critical data now displays directly on infrastructure elements. No more clicking through menus to find basic information like available GPUs or job requirements.
Burst budget pool: Unspent budget accumulates for big training runs instead of disappearing. Gives management predictable spending while letting developers scale compute without approval workflows. Eliminates use-it-or-lose-it waste.
Coming soon: Network topology visualization for distributed training placement, mega-cluster rollups for 100K+ GPU deployments, and visual GPU differentiation by performance and VRAM capacity.
This update represents a turning point in development. After showcasing Clustercraft (formerly 3D Compute Manager) to operations teams, ML engineers, and infrastructure leaders, we gathered extensive feedback through playtesting sessions. This update addresses the most critical usability gaps: making infrastructure state instantly visible and eliminating information hunting.
The Problem: Information Overload
Playtesting revealed a consistent pattern: new users struggled to understand what resources they had available and where capacity existed. The interface required clicking through panels to see basic information like GPU counts, space availability, and job requirements.
Operations teams need to make quick decisions under pressure. Hunting for information breaks flow and creates cognitive overhead that doesn’t exist when managing physical infrastructure where you can see capacity at a glance.
The Solution: At-a-Glance Resource Labels

Every infrastructure element now displays critical information directly on the 3D representation:
Jobs show GPU requirements before placement
Spaces display available capacity in real-time
Clusters indicate total resources and utilization
Information updates live as infrastructure changes
Result: Users can now scan the entire infrastructure landscape and identify available capacity in seconds rather than minutes. Decision-making becomes spatial and intuitive rather than abstract and text-based.
The Problem: Navigation at Scale
As deployments grow to dozens of regions across multiple cloud providers, users lost track of their position and struggled to move between infrastructure locations efficiently. Zooming and panning became tedious when managing global deployments.
This mirrors real operations challenges where teams need to quickly shift attention between different regions, providers, or resource types without losing context.
The Solution: Mini-Map Navigation

A persistent mini-map in the bottom corner provides:
Overview of entire infrastructure deployment across all regions
One-click navigation to any location
Real-time updates as infrastructure changes
Spatial awareness of resource distribution
Result: Operations teams can now manage global deployments with the same ease as single-cluster environments. Navigation time drops from frustrating to instant.
The Problem: Budget Inflexibility
Traditional enterprise GPU budgeting forces organizations into rigid resource allocation. Teams either reserve too much capacity (wasting budget) or too little (creating bottlenecks). There’s no mechanism for flexible burst capacity when workloads spike.
AI Infra Summit conversations revealed this as a major pain point: organizations want baseline reserved capacity plus the ability to burst when needed without complex approval processes.
The Solution: Burst Budget Pool
The system now separates budget into two categories:
Reserved capacity: Fixed infrastructure committed long-term
Burst budget: Accumulated unspent funds available for temporary capacity
How it works:
Budget gets allocated hourly based on organizational limits
Reserved infrastructure consumes predictable baseline costs
Unspent budget accumulates into burst pool
Teams can access burst capacity instantly when needed
CFO patience mechanics encourage efficient utilization
Result: Organizations maintain stable baseline infrastructure while gaining flexibility to handle spikes, experiments, and temporary large-scale training runs. Budget becomes a tool for enabling work rather than restricting it.
The Problem: Network Topology Blindness
Infrastructure provisioning often ignores network topology, leading to jobs that span multiple switches and suffer communication bottlenecks. Operations teams can’t visualize how nodes are connected or understand why certain workload placements perform poorly.
Distributed training performance depends heavily on GPU interconnect quality. Poor placement decisions waste compute time and budget.
The Solution: Network Visualization (In Progress)
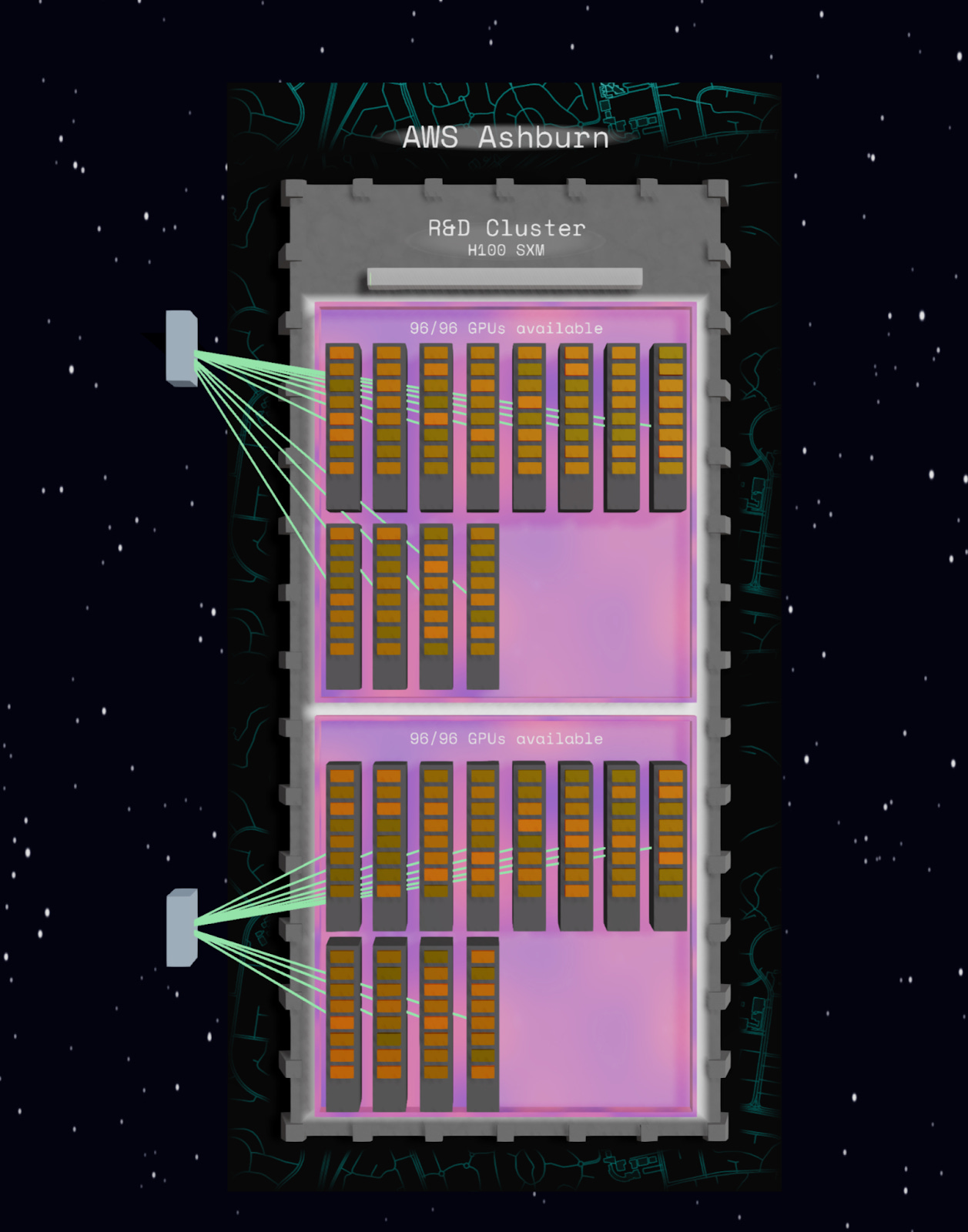
Early implementation shows node connectivity within clusters:
Visual representation of switch hierarchies
Hop count indication between nodes
Clear identification of tightly-connected GPU groups
Foundation for network-aware job placement
Result: When complete, this feature will enable operations teams to place distributed workloads optimally, ensuring GPUs with high communication requirements get provisioned on tightly-connected hardware.
Future Direction: GPU Size Differentiation
Current feedback indicates all GPUs look identical regardless of capability. Users can’t distinguish between A100s with 80GB VRAM and smaller instances with 16GB just by looking at the interface.
Planned solution:
GPU width represents VRAM capacity
GPU height represents computational performance (FP16 flops)
Physical area becomes a meaningful proxy for capability
Larger GPUs visually command more space, matching their resource value
This creates intuitive capacity planning where you can see at a glance whether infrastructure can handle memory-intensive models or compute-bound workloads.
Lessons from Real User Feedback
Rather than building features we thought were important, we’re now solving problems real operations teams encounter daily:
Speed matters: Every click, every navigation action needs to be instant
Information hierarchy is critical: Show the most important data first, details on demand
Budget flexibility drives adoption: Teams want safety rails, not roadblocks
Physical intuition beats abstraction: Spatial representation feels natural to operations teams
These insights are shaping every design decision as we move toward production release.
Strong Compute provides visual GPU infrastructure management across all major cloud providers. Subscribe to https://words.strongcompute.com for weekly product updates and follow our https://www.youtube.com/@strongcompute for video demos of new features.
Try Clustercraft: https://clustercraft.com