
The Future of GPU Infrastructure Management is Here: Introducing Strong Compute's 3D Compute Manager
Visual, intuitive control over your entire GPU compute infrastructure

Managing GPU infrastructure across multiple cloud providers has always been a complex, abstract challenge. Working between spreadsheets, dashboards, half a dozen terminals just to understand what resources you have, where they are, and how they're being used. It’s time for a better way.
Today, we're excited to introduce Strong Compute's 3D Compute Manager — a revolutionary visual interface that transforms how operations teams manage GPU compute infrastructure.
Visual Infrastructure Management Matters
Traditional infrastructure management tools force you to think in abstractions. You're managing "instances" and "clusters" without a clear sense of the physical reality beneath and with no clear way to link hardware health with workload performance and cost. These disconnects leads to inefficiencies, miscommunications, and costly mistakes.
Our 3D Compute Manager bridges this gap by providing a spatial, intuitive representation of your actual hardware. Temperatures, throughput, cost, experiment performance are all cross referenced.
When you see a cluster in our interface, you're looking at a visual representation of real physical servers with real GPUs, organized as they exist in the data center.
What Makes the 3D Compute Manager Different
Real-Time Visual Infrastructure
Every element you see represents actual physical resources. Clusters, nodes, GPUs each with real GPUs that you can monitor and manage in real-time. The health data updates live.
Lift and Shift in one click
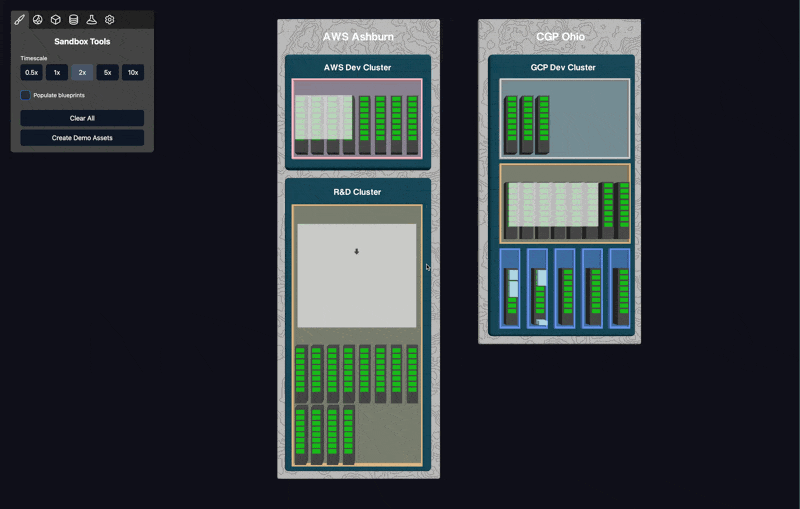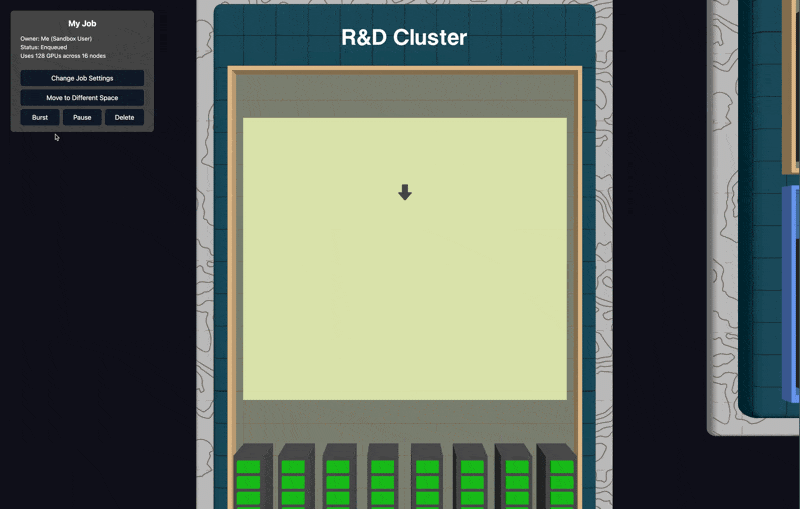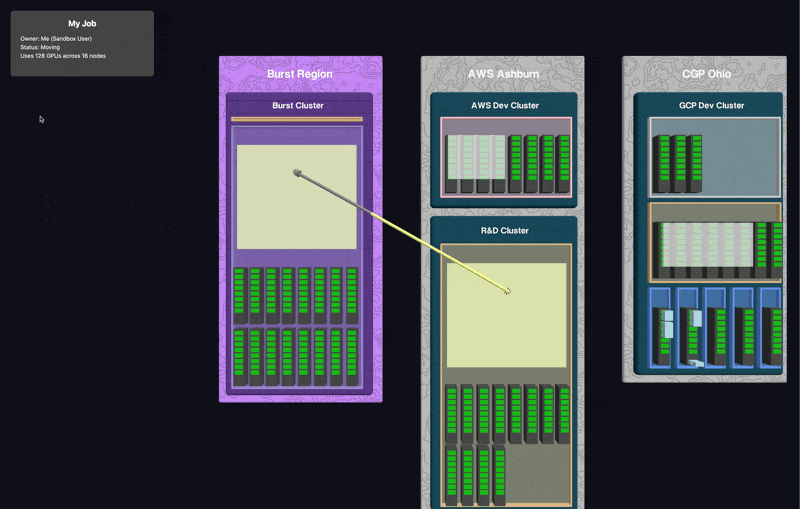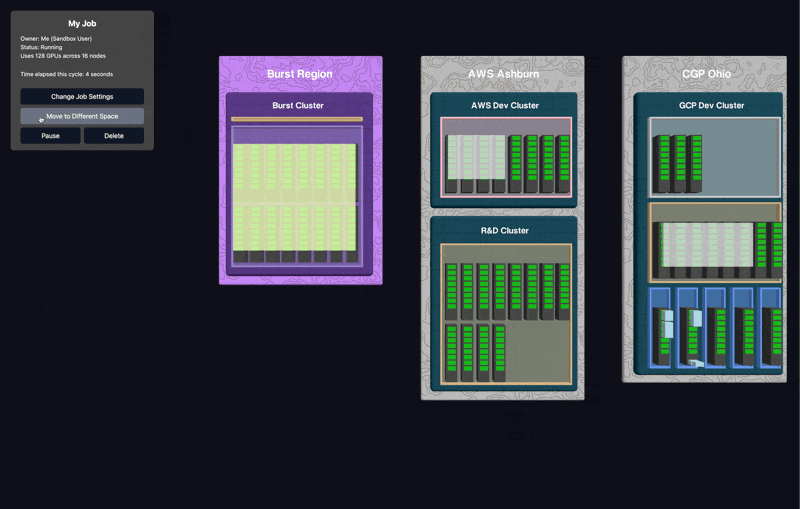
Moving workloads between clusters used to require complex migrations and significant downtime. With our 3D interface, you simply drag and drop jobs between spaces, clusters, or even regions.
The system handles all the underlying complexity: workload state saving, provisioning, storage clustering, data movement, network configuration. Workloads pick up where they left unaware they’re now on a new provider, even on different GPUs or a different networking stack.
Intelligent Space Management
Resources are organized into logical "spaces" that help compartmentalize different types of workloads:
Workstation Spaces: Where users spin up containers and interactive environments
Dedicated Spaces: For bin packed longer term jobs, like a slurm queue.
Time-Cycled Spaces: Shared compute that rotates between different jobs, great for maximising resources, and allowing for instant feedback on short test runs of new pipelines.
This organization makes it easy to allocate resources appropriately and ensure different workload types don't interfere with each other.
One-Click Burst Scaling
When you have a job that requires more resources than your current infrastructure can provide, traditional solutions involve lengthy procurement processes or complex auto-scaling configurations. Our "burst" feature lets you instantly provision additional resources from our network of cloud providers. These resources exist only as long as needed and automatically disappear when your job completes.
Burst Workstations - to temporarily access additional interactive compute i.e. a container you can log into, great if you need bigger or extra GPUs than your reserved clusters to get work done.
Burst Jobs - grab a whole cluster as spot or on demand to take workloads out of your queue or access larger resources than available in your reserved clusters.
Built for ML Teams
ML Engineers get visual confirmation of resource allocation and can easily move training jobs to optimal hardware configurations.
Ops can manage multi-cloud infrastructure through a single, intuitive interface instead of juggling multiple provider dashboards.
Finance can control costs. Finally.
Execs can see what’s going on without commissioning decks and waiting days or weeks, and make decisions immediately.
Most importantly, it helps get everyone working with each other, letting R&D and ops work hand in hand rather than passing blame or building countermeasures to thwart each other’s system controls.
A Fast and Solid Core
Strong Compute is powered by:
60GB/sec cloud-to-cloud transit — the world's fastest inter-cloud data movement
7.8-second container launch — industry-leading deployment speed
Multi-provider integration — seamless management across AWS, GCP, Azure, Oracle, Lambda Labs, and more
Enterprise security — ISO27001, SOC2, HIPAA, and GDPR compliance underway
Current Status and What's Next
The 3D Manager launches today as a sandbox environment where you can experience the interface and understand how it works. We're running live platform data on our own clusters, and we’re ready to integrate with yours.
This is the foundation for infrastructure management that's as intuitive as moving objects in the physical world.
Try it now
The sandbox environment is available now, jump on:
Try the 3D Manager sandbox and experience visual infrastructure control for yourself.
Subscribe to words.strongcompute.com for weekly product updates and our YouTube channel for weekly how-tos and dev diaries.
Strong Compute provides complete command and control for GPU compute, backed by an on-call MLOps and AI development team. Contact us to learn more about how we can transform your infrastructure management.